Edwin B. Olson, eolson@mit.edu
The development of cryptosystems was an essential evolution in communication. Study of these communication systems and probabilistic analysis of encrypted channels facilitated the development of more complicated systems. The probabilistic analysis of encrypted messages was facilitated by the use of computer systems, and allowed detailed examination of the entropy (information) contained in messages. Studies were extended to examine the entropy of arbitrary messages in different languages. This paper examines the results of Claude Shannon’s studies, and complements his results with new data obtained using the higher-power computation systems available today.
A. S. Eddington mused that "If an army of monkeys were strumming on typewriters they might write all the books in the British Museum" [1] which elicits the common cliché, "a thousand monkeys at a thousand typewriters will one day reproduce all of the works of Shakespeare." An assertion like this is clearly true given infinite time; however, the amount of time necessary is a subject often debated.
A naïve approach might simplify the problem by assuming a language consisting of 27 letters: the letters A through Z, plus space. Randomly selecting any one letter would have the probability 1/27. Randomly selecting a word (given that the average word length in the English language is roughly five) would be about 1/275. The works of Shakespeare total some 5.4 million characters [2], so the probability of generating this work, through a purely random process, is roughly 1 in 107729400. A trillion monkeys working for a trillion years, typing at the rate of a trillion characters per second would equate to only about 1036 trials, a totally insignificant amount when compared to 107729400.
Fortunately for the monkeys, the above approach is simplistic in that it ignores entropy. As Shannon discusses in A Mathematical Theory of Communication, the information contained in a transmission with a priori probability P, as measured in bits, is log2 (1/P). The naïve approach, considered above, assumes that each of the 27 letters is equally probable. Therefore, the amount of information contained in each letter is log2 27, which is about 4.75 bits. Human languages are heavily redundant and the probability of any particular letter is rarely as low as 1/27. English, as is commonly known, has a high occurrence of the letters E, R, S, and T. These letters occur with probabilities greater than 1/27. Therefore we can determine that the absolute worst case is that the 5.4 megabyte collection of Shakespearean works contains at most 4.75*5.4 or 25.65million bits.
English also contains a significant amount of redundancy. In the extreme case, the letter "U" in the sequence "QU" is completely redundant and can be omitted without loss of information, since U always follows Q. More generally, the probability distribution for a given letter changes based on the preceding letters. The number of previous letters considered when determining the most likely next letter is an approximation whose order is equal to the number of previous letters used plus one. For example, a first-order approximation considers no previous letters but includes biases for common letters like E, R, S, and T. A second-order approximation considers the previous letter; if the previous letter is Q, then the next letter is assuredly U. A third-order approximation considers the previous two letters; the letter E is likely to follow "TH", and so on.
These considerations allow a modified view of the monkeys-on-typewriters problem. The typewriter can assist the monkey by changing the size of the keys to reflect the probabilities of those letters given the last few letters typed. For instance, if the monkey hits Q, the typewriter increases the size of the U key so that it fills the entire keyboard. The monkey randomly selects a location on the keyboard, as he always does, but thanks to the keyboard, he does so in a probabilistic way. The result is that the output looks increasingly like English, and the probability that the monkeys can generate all the works of Shakespeare increases extraordinarily.
The question of how much entropy exists in written text directly addresses the probabilities of the monkeys’ success. Measuring this entropy is challenging, but doing so is interesting and applicable to a number of other related fields. Communications systems, in order to increase throughput, should transmit the bare minimum amount of information; such a system should not transmit ten bits to encode a letter if the letter contains only four bits of information. Cryptographic systems are extremely sensitive to the amount of entropy in a message being encrypted. If the redundancy of the message is high (and the entropy therefore low), it is easier for an adversary to decrypt the message by exploiting the redundancy.
This paper will address the measure of entropy in English, expanding on Shannon’s work through third-order approximations by providing fourth and fifth-order approximations. Redundancy will be used to break a simple substitution cipher as an example and illustrate the difference between the size of a key and the information contained in the key. Finally, significant observations about the properties of written languages will be noted.
Several approximations of English were made using a complete collection of the works of Shakespeare as a model, totaling over 5.4 million characters. Shannon, in several of his works, generated random text through the consultation of tables of monogram and digram letter frequencies. When these tables proved insufficient (as they were for higher-order simulations), he consulted books from his library. His simulations included zero-order, first-order, second-order, and third-order by letter. He also conducted first-order and second-order simulations by word. Due to the labor involved, he stopped at this point. The author, using computers of today’s capability, has extended the approximations to the tenth order by letter. Approximations by word are a crutch used by Shannon to simulate higher-order letter simulations, but with true and accurate higher-order simulations, they can be neglected. Below, both Shannon’s and the author’s results are reviewed.
| Approximation Order | Shannon | Author |
|---|---|---|
| 0 | XFOML RXHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGXYD QPAAMKBZAACIBZLHJQD | DPSIMYWHNC QRXMLXHDVMRWXSJUGAVPTJWAVUMRWOQLU BXVYTYIVODRFBKBREFJCAKMULCEOSPHTBBGU DDCWVIXUZDODMQTLCCWEGJMWGUMH VWSZZNIW BUCEMOVEPMGKFNJRYPAZWPTHHGFUOAIFUKJVOTZCEFB HKFUOFS VKGBRAKUATZJSYDVFBXKWOZSNDLBJCQDNWUTWDBLLAUDNMYSCKRONPF IRQRTFJVQSNAVPLWEUOGVLYYKELMIQMQGRGPMEJBWMSGQCBJMPPGPBTPFDAOJBDEI TUTCKPOBKTULBVPQADGJSMMIPKJSPRGH ZKDBANUJNVDB UEGCMHDUWOSCSJJZYYYHAOICIGPSKQSDJNVVUYDPALRSJPRGB DOBGLTORHGQMNIWPCFIAJMQUSICHOYIRL MLHASPWHAYQLMHRJHPVYYMVPIIMGOYV YBPPQKMGXRRIYXRVLAHI |
| 1 | OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTT OOBTTVA NAH BRL | DSFEAA IIAHYP TTIOK E BSMUTINL ROIAATTSHMO NEDP OELE OL HATDT M MY C AGM AITNETCL M H I ATNETPHTN HUERA OTNID OTP IISSS BI UTB S T GVPRELRARY EMC OUU OYRHPR N DHBYOH S TSMA SO S TL HHHR ORAAYDWONHIECSRDUTV YE S EMABLIHHVTDAE DINDOWOSRHYNU MOWU KIUHRTDL OHOIHLRO BNNHSLNCT OESET A STIWSFWYE AO GHR LRNED E M L H DONGP VTVN OEI E EWN TTEC A LH L AD IIGDH ASE EEWHOSSJGCWOEGN NC HLD ESTG OU F RY ASEEN LNILAD LTNW F OM UF RHSWBV RE ENINRCTVO A OEONWALTN SECI BTTA |
| 2 | ON IE ANTSOUTINYS ARE T INCTORE ST BE S DEAMY ACHIN DILONASIVE TUCOOWE AT TEASONARE FUSO TIZIN ANDY TOBE SEACE CTISBE | U T FOWSITOF TCOFOMES OMAIND T M IRSHA NENOWIVEDIN ASHOU GRORSWA K TSIMES COURO S PILIND STINDEM ATINGESARE OTSAIER Y THE BL ULUR RT WIE LVE IS F TH G T CHE TOF YO E NGH E THOUS THARSHESTITEY T MEITANTWHOUG FONSHITWE S R S E T NY MEURISE IAILUS F FOFELLLBY SOTHOUCERR A FLE CHAREAN MY TSLIRT AS SWITHES OUECOUNI IAPRE HISTHEX THATHEWIND THALORR W S PRIS G NSE OOREYO LO F FUGHECR ART MES MAREAREL GRUCY MOWHEST THELEN NON SHENOD WEDIOONBR ONT RVE TOFFIS E TEIEXPH T WOREI HE ATIN |
| 3 | IN NO IST LAT WHEY CRATICT FROURE BIRS GROCID PONDENON OF DEMONSTURES OF THE REPTAGIN IS REGOACTIONA OF CRE | ESPEME TH POL PRAIRD HIME SO COM WHAT AND SHD WINLITHERE O ENCENTES PLABOD AND LET ARE US SELL THATIN MUS QUE SO IT TRIUS SOLK AN HOUT O OF HE ON CLART EXCENS DICHALAES AFT IS TINKIL HERGAGAING BROCCUR HIMPERFEADIELL THOU THEY GRIEFFERVICKLY DEEPS TO THABLE BUT TH LOSTRIBUS SPUR ANTE FATS UP TH AND THER CONTONIEF LOOLEGGENJOULD AND TH YOUT PLING WART THE BUND THE QUART THERE THE DRECIOURS PRACEAKE OR IT LE AND BEYLOR FEAP OCKINTIMALL MY FE ALL TO CAPPONE LES FAT THE WAR TH ED |
| 4 | THEN O THAT CHAIN WHAT LOVE ALL WOULD THE PROM AY THY LIVETOUCESTER IN MOTH AND IS WHICH YOU MORESOLD YOU ARE AND LEASONS FOR THES HER TIME AIR FOR TO THEE NIGHNES ARE THE FOULD EXIT DIAN YOU WILL GO I MUCH A GREG ALLY AND AS STE TO THAT GENTLEME IN MY LORD WIFE HE KING OUTFACE THIS BY BLING BE THOU TAL CAN WILL HIM BECOMEED GIBBLE RICH THY OF THES NOTABLE ENT THANK SHAL ME WORD BUT THIS TAKE AND COME TO THY TALKING SLUMNIAN MY HAVE NOT RIGONE SPER PROVE MOON AND DID MUST THE | |
| 5 | FACE OF ALL LUCIUS SO MARKS OF LUSTY THAT THEIR RAGS SIR I AM CONFECT TO THER SUFFERENTS AND BIND MAKE THAT THINKS OF THE LOOK LIES MAY WITCH HIM HORT COME THAT WILL PEALD YOU BEEN AWAY ANSWER THAT WHILE WAS IT BY WOULD I PERCE THE POMFRET WHEN COLOURISHES AND PLACE AND WE SHALL BE SHALL THY PLAGUE COULD I MARIA THE WOULD SCORD CHOP OF THOU DISPOSE NOT SLANDO A DANGER OF MANLY THE CAREST OF SOLDIERS FORTH SOME PROBATION ASS TIS THE FINGER ARGO TO THEY STAGENTLEMAN IN OF WE T |
Past fifth order, so much state is accumulated that the "random" text has very little freedom at all due to the fact that the database simply does not contain enough samples. As the order increases to seven, eight, and nine, the random text generator begins to quote directly from the database, or fail to generate any text at all. Therefore, higher order approximations, using the Shakespeare database, are meaningless. However, the interest of this paper is not in the generation of statistically-consistent but meaningless English, but rather the measure of entropy in real English.
The problem of monkeys on typewriters attempting to compose Shakespeare can again be of use. Suppose that the typewriter reapportions keyboard space to reflect the proper letter distribution according to the previous n letters. How much entropy is there in text? By approximating how long it would take a monkey to produce Shakespeare using the best statistical "typewriter" available, we can answer the question.
A database of all of Shakespeare’s work was again assembled, with one intentional omission: his first Sonnet. If the typewriter knows all of Shakespeare’s other work, can it help produce the missing Sonnet? There are several assumptions at work involving the consistency of Shakespeare’s work and the validity of using Shakespeare’s other work to generate a missing piece, but the assumptions are intuitively reasonable and will not be rigorously investigated in this paper.
The program is provided the previously described database and a "seed", corresponding to the first n letters of Sonnet One, so that the (n+1)-order approximation can begin. The program looks for all occurrences of the "n" letter seed and builds a probability density table for the (n+1)st letter. The correct letter is then supplied to the program, and the program reports the a priori probability assigned to that letter.
This process continues for many letters, until the geometric mean of the individual probabilities converges to reasonable precision (the mean converges quite rapidly; in this experiment the mean was taken after about twenty iterations.) The program was run ten separate times, each time calculating the geometric mean of all the probabilities encountered for each letter.
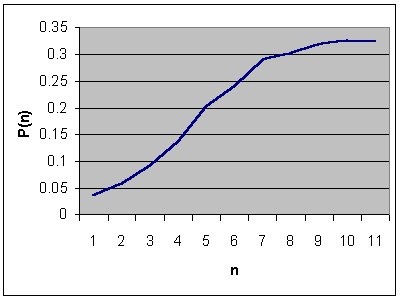
Let P(n) be the geometric mean described above for a typewriter that remembers n letters. For a text consisting of L letters, the probability of generating L letters which are identical to a Shakespearean passage is PL. For the monkeys to succeed in becoming successful authors, P must be as high as possible so that this overall probability is minimized.
Though the database of Shakespearean works is several megabytes, it becomes statistically small as n increases. Beyond eight or so, many n-letter sequences found in Sonnet One can not be found anywhere in the collected works (an event called a "miss".) While the problem is only truly solvable by increasing the sample space, the problem was combated by reverting to an approximation of slightly lower order (and therefore more likely to not miss) when necessary. This workaround leads to P(n) values lower than the actual value for large n since not all samples used to calculate P(n) are fully order (n+1).
Experimental values for P(n) versus n are displayed below. Misses occurred increasingly frequently as n increased beyond six. P(6) had about 2.5% misses, P(7) had about 5%, P(8) had about 10%, P(9) had about 15%, and P(10) had a miss rate of about 20%. Therefore, it is likely that while the true curve follows the curve very closely for n less than 7, it is slightly higher for the remainder.
The maximum P(n) was P(9)=0.3258. This means that the average chance that the next key hit would be the correct "Shakespearean" key was 32.58%. This is significantly higher than the naïve, dumb typewriter scenario discussed earlier which had P(0)=1/27 or 3.7%.
Using the standard definition of information, we can determine that an upper-bound on the amount of information stored per character is log2 (1/P(9)) which is 1.62 bits. Note that this figure is accurate only for this example, but it is reasonable to assume that similar results would be obtained with different data.
At 1.62 bits of data per letter, the 5.4 million letter collection of Shakespeare contains only 8,736,884 bits of data. When compared to the original estimate of 25,650,000 bits, one can see that the monkeys’ task has been enormously simplified. Of course, the monkeys will still be very busy if they wish to succeed. It would still take 1071534 sets of a trillion monkeys each, all typing at the rate of a trillion characters per second, working for a trillion years. A more sophisticated analysis incorporating grammar checking or other techniques may succeed in lowering the upper bound even more.
It is interesting to note that the final figure determined for the amount of information in Shakespeare’s books, 8,736,884 bits, equates to a 1.1 MB file if stored in a conventional way on a computer. The author obtained the collection of Shakespeare compressed in ".zip" format, which, like any compression algorithm, attempts to strip a file of redundancy and reduce it to pure information. If the Shakespeare collection is reformatted to use only the 27-character alphabet used in the simulations, PKZIP is capable of reducing the file to 1.7MB, indicating that the 32.58% prediction of P(8) is superior to the PKZIP compression format for this example. PKZIP obtains an effective P(PKZIP) value of 16.0%.
Ideally, when transmitting encrypted data, an attacker cannot feasibly determine the original plaintext from the encrypted ciphertext. What exactly does this mean? It means that the attacker lacks information—the key—which is necessary in order to read the ciphertext (we assume that the attacker knows the cryptographic protocol.) The information contained in the key, therefore, is a very important number.
The Data Encryption Standard, DES, uses a 56-bit key. Ideally, the 56-bit key contains exactly 56 bits of information. It is impossible for it to contain more than 56 bits worth of information, but it is very possible for it to contain less. Suppose, for example, that half of the possible DES keys were invalid, and were thus never used. The 56-bit key would only contain 55 bits of information.
Suppose that information can somehow be extracted from the ciphertext or from auxiliary (but publicly available sources). This information can reduce the amount of information needed to decrypt the file. A good example is RSA. RSA uses keys of large size, on the order of 512 or more bits. If RSA was perfect, then the key would encode 512 bits of information and RSA would require exponential time to solve (2512 steps). However, the mathematical problem which RSA is based upon (factorization) can be solved in sub-exponential time; consequently, the information contained in the key is somewhat smaller than 512 bits. The exact amount of entropy in keys is a critical element of a cryptosystem and continues to be investigated.
A clear example of a cipher system that leaks information about the plaintext message is a simple substitution cipher, a cipher where each letter is mapped to exactly one other letter. For example, the word "HELLO" may be encrypted to "ABCCD" or "MBRRZ". Clearly, a large amount of information remains in the file, including the frequencies of the individual letters as well as the pattern of the letters.
The key space for a simple substitution cipher is very large: 26*25*24…*1 which equals 26!, or approximately 1027. If a simple substitution cipher was perfect, a simple substitution cipher would be extremely difficult to compromise, since it corresponds to 93 bits of information (versus the 64 bits common in modern ciphers). Knowing that simple substitution ciphers are trivial to solve, the question becomes not "how big is the key space?" but "how much information does the key contain?".
Consider a program which attempts to put an upper bound on the information stored in a key for a simple substitution cipher. Several approaches are possible, including consulting directly a table of probabilities to determine the likelihood of various solutions (and therefore keys). A simple-substitution-cipher-solving program was implemented, though it is of significantly greater complexity. It assumes that the key permutes only letters, and that a space in the plaintext always generates a space in the ciphertext. This presents the special property that words are preserved and easily distinguishable, however, the analysis that follows could be extended to a more general 27-character cipher system.
The program analyzes ciphertext by observing the pattern of letters in words. For example, some words have multiple occurrences of the same letter. The number of words in the English language which exhibit the same letter pattern is generally quite small for any arbitrary pattern. This fact is used to quickly produce lists of candidate words for encrypted words through the consultation of a dictionary. For example, "ADAPTABLE", "EMERGENCY", and "NONLINEAR" all have the letter pattern "ABACDAEFG". From the sizes of these lists, an upper bound can be determined on the information needed to decipher the puzzle, and hence, the information or entropy contained in the key. Note that the entropy will vary from word to word. This word-list generation produces upper bounds far lower than a procedure using only letter frequency, but the true upper bound is clearly much lower. For example, this program does not take into account word probability (i.e., some words are more common than others) or grammar. If these elements were taken into account, a much lower upper bound on the entropy in a message could be calculated.
Suppose the first ciphertext word in the puzzle has C1 candidate plaintext words of matching letter pattern, the second C2, and so on for I words. To resolve which plaintext word corresponds to the ciphertext word for word n requires log2(Cn) bits of information. However, the information required to solve the entire message is not the sum of log2(Cx) for all x; the words are not independently encoded and solving one word greatly reduces the amount of information required to solve future words. The total amount of information needed to decode the puzzle is somewhere between the smallest log2(Cn) and the sum of log2(Cx) for all x. It tends to be much closer to the former.
A number of messages were encrypted, and the key was discarded. The ciphertext was then passed to a simple-substitution cipher program, written by the author. During the process of determining the plaintext from the cipher text, the program calculates the amount of information that was "guessed" in order to find the answer. This puts an upper-bound on the amount of information stored within the key, since determining the plaintext from the ciphertext and key requires no additional information. It should be noted that the key used to encrypt the message does not affect the measurements below; the same may or may not be true for other cipher systems.
Message Measured Entropy (bits)
Once upon a time there lived a family of three bears. 19.4
We the people of the United States 13.76
We the people of the United States in order to form a more perfect union 6.3
We the people of the United States in order to form a more perfect union establish justice, insure domestic tranquility provide for the common defense 5.8
Adding manpower to a late software project makes it later. 7.3
This is a test of the emergency broadcast system. 5.2
Now is the time for all good men to come to the aid of their country. 27.8
Quickly examining the results, it is evident that the amount of entropy is insignificant compared to the estimate of 93 bits, assuming that a simple substitution cipher was perfect. Further, as the message length increases, more information can be extracted from the ciphertext, leaving less information to be extracted from the key.
Generalizations and Conclusions Regarding the Entropy in Written Language
There is one basic conclusion that can be made from the results obtained in this paper. Written English has surprisingly little information in it. The applications of this knowledge range from helping monkeys generate the works of William Shakespeare to reducing the difficulty of solving a cryptogram by enormous amounts.
Using an intelligent typewriter, a monkey’s chances of producing Shakespearean text increase extraordinarily. This exploits the fact that some letters are very likely to follow other particular letters. The typewriter can, in essence, be run "backwards" to determine the probability that it would generate a particular Shakespearean Sonnet. The probability can be converted into the number of bits of information in that passage. The resulting information density of Shakespeare is quite low.
The statistical peculiarities of English can be applied to cryptography. By exploiting information in the ciphertext, the amount of information in the key needed for decryption is reduced, substantially in the case of a simple substitution cipher. A strong lesson in cryptography is learned: the key should contain information completely unrelated and independent from the ciphertext. If an similarity exists, a clever attacker could reduce the strength of the cipher by extracting that information from the ciphertext, rather than exerting effort to "guess" it in a brute-force attack.
The process of encrypting a message can be analyzed in a different way. There is an infinite amount of information in the Universe. Suppose a plaintext message contains the set of information P. This message is then encrypted. The information in P is divided into the key (K) and ciphertext (C). K+C contains P, and perhaps some other unrelated information, but K+C also can be deterministically reduced to just P through some decryption process. The security of the cipher is in the degree of independence between K and C.
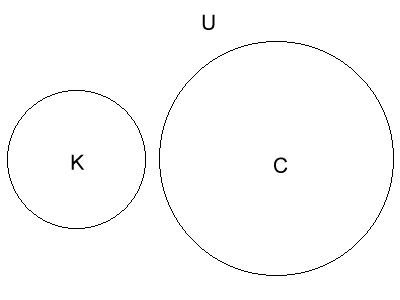 |
| A perfect cypher, such as a one-time-pad has no overlap between K and C |
|---|
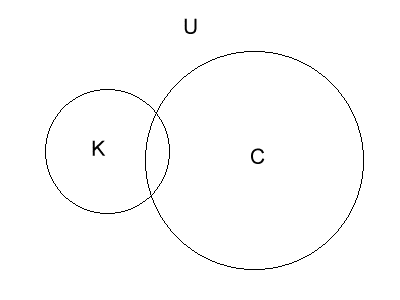 |
| An average cypher has a ciphertext from which key information can be determined from. The degree of overlap indicates the weakness of the cipher. |
|---|
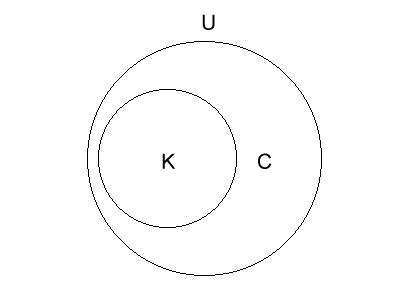 |
| A hopeless cipher can be decrypted without any additional information, due to the fact that the ciphertext contains so much information. Example: some simple substitution ciphers. |
|---|
[1] A.S. Eddington, The Nature of the Physical World
[2] Project Gutenberg. Shakespeare Archive Collection
[3] Shannon, Claude, A Mathematical Theory of Communication
[4] Shannon, Claude, A Mathematical Theory of Cryptography
Several computer programs were written to generate examples for this paper. They were written in C and only utilize a text interface. While compiled under UNIX, they should be readily portable to other platforms. The Shakespeare library can be obtained from Project Gutenberg. All should be compilable with a simple invocaton of gcc, though some require linking with the math library (through the -lm option).
Zero-order approximation: zeroapprox.c
Random text through order 5: generaterandom.c
Shakespeare P(n) calculation: computep.c
Simple Substitution Cipher Solving: (directory)